CHI 2023: Quick Look at How to Interpret Your Reviews

Julie R. Williamson (Papers Co-Chair 2022 and 2023)
The first round of the review process is complete, and authors will now know if they have been invited to revise and resubmit (at least one reviewer recommends Revise and Resubmit or Better). This short post will help you understand how to interpret your reviews and decide if you want to revise and resubmit for CHI 2023.
In 2023, we received 3182 submissions.
- 48.9% were invited to revise and resubmit
- 43.7% were rejected after review
- 7.4% were not sent for external review (withdrawn, desk rejected, quick rejected).
A significant proportion of papers invited to revise and resubmit will not be accepted to CHI 2023. Estimating based on previous years, we expect about half of the invited papers to be eventually rejected during the PC meeting in January 2023.
Our analysis of 2022 review process data demonstrates that papers that do not have strongly supportive reviews do not have a good chance to be accepted. This post will give some updated numbers to help interpret your reviews and decide if you want to participate in revise and resubmit. Authors do not need to notify the programme committee about their decision to revise and resubmit.
Review Scales
Before we go into the reviews, it’s important to remember what scales have been used during the CHI 2023 review process. Reviewers and ACs provide a recommendation (recommendation category out of 5 choices) and can further contextualise their recommendation based on originality, significance, and rigour (each a 5 point ordinal scale).
Recommendation
| Short Name | On Review Form | Threshold for Revise and Resubmit |
|---|---|---|
| A | I recommend Accept with Minor Revisions | Yes |
| ARR | I can go with either Accept with Minor Revisions or Revise and Resubmit | Yes |
| RR | I recommend Revise and Resubmit | Yes |
| RRX | I can go with either Reject or Revise and Resubmit | No |
| X | I recommend Reject | No |
Ordinal Scales
Ordinal scales are used to better contextualise reviewer recommendations, and should be considered as secondary to the reviewer recommendation.
| Order | On Review Form |
|---|---|
| 5 | Very high |
| 4 | High |
| 3 | Medium |
| 2 | Low |
| 1 | Very low |
Proportion of Supportive Reviews
The proportion of supportive reviews (recommendations of RR or better) was a good indicator of paper success in 2022. Below, we provide bar charts showing a few ways of counting “proportion of supportive reviews.” In all cases, supportive means the actual recommendation of the reviewer, not the text of the review.
Figure 1 shows the proportion of reviewers recommending RR or better. Papers that have only one or two supportive reviews are very unlikely to be accepted and authors should consider if they want to revise and resubmit.

Another way to look at how supportive reviews are is to consider how many reviewers recommend ARR or better. Papers where no reviewers recommend ARR or better are unlikely to be accepted.

A very positive way to look at how supportive reviews are is to consider how many reviewers recommend A, which is the most positive recommendation possible. However, 86% papers have no reviewers recommending A. This is an unfortunate statistic for our community, as our review process might be fairly criticized for being overly negative. This also means a fair number of papers where no reviewer recommends A in the first round will be accepted after the PC meeting in January 2023, showing the positive impact a revision cycle can have. It’s worth reflecting how we can improve the quality of submissions and the tone of reviews moving forward.

Subcommittees
Each year, there is some variation between subcommittees. We provide this data for transparency and reflection on how different subcommittees are running their review process this year.

Conclusion
This short overview of the review data should give you some additional context when analysing your reviews and deciding if you want to revise and resubmit. These give some indications, but all decisions are reached after discussion at the PC meeting. There are no deterministic positive or negative outcomes, all decisions are human decisions by the programme committee.
Good luck with your paper revisions, or if you are not revising and resubmitting, good luck with your future plans for your work. We hope the review process has provided something helpful in improving your papers and working towards your next publications.
Data Tables
Note some numbers may not add up to official totals due to conflicts, late reviews, and other missing data at time of writing.
Figure 1
Figure Description: Proportion of reviewers recommending RR or better. Authors with at least 75% of reviewers recommending RR or better make up the top 32% of submissions. See data table:
| Rejected | Revise and Resubmit | |
|---|---|---|
| 0.0% | 1624 | 0 |
| 25% | 0 | 246 |
| 50% | 0 | 298 |
| 75% | 0 | 473 |
| 100% | 0 | 541 |
Figure 2
Figure Description: Proportion of reviewers recommending “ARR” or better. Papers where at least half of the reviewers recommend “ARR” or better represent the top 14% of submissions. See data table:
| Rejected | Revise and Resubmit | |
|---|---|---|
| 0.0% | 1624 | 585 |
| 25% | 0 | 538 |
| 50% | 0 | 211 |
| 75% | 0 | 118 |
| 100% | 0 | 106 |
Figure 3
Figure Description: Proportion of reviewers recommending A. Papers where all reviewers recommend A are rare, representing just .5% of submissions. See data table:
| Rejected | Revise and Resubmit | |
|---|---|---|
| 0.0% | 1624 | 1181 |
| 25% | 0 | 287 |
| 50% | 0 | 55 |
| 75% | 0 | 19 |
| 100% | 0 | 16 |
Figure 4
Figure Description: Breakdown of QR, X, and RR for all subcommittees. See data table:
| QR (%) | X (%) | RR (%) | |
|---|---|---|---|
| Accessibility and Aging A, Accessibility joint | 0.0 | 0.463918 | 0.536082 |
| Accessibility and Aging B, Accessibility joint | 0.020833 | 0.375000 | 0.593750 |
| Blending Interaction: Engineering Interactive Systems & Tools | 0.025253 | 0.469697 | 0.505051 |
| Building Devices: Hardware, Materials, and Fabrication | 0.010638 | 0.329787 | 0.659574 |
| Computational Interaction | 0.016854 | 0.443820 | 0.533708 |
| Critical and Sustainable Computing | 0.033898 | 0.338983 | 0.627119 |
| Design A, Design joint | 0.033058 | 0.545455 | 0.421488 |
| Design B, Design joint | 0.016949 | 0.432203 | 0.550847 |
| Games and Play | 0.053435 | 0.473282 | 0.473282 |
| Health | 0.116505 | 0.451456 | 0.432039 |
| Interacting with Devices: Interaction Techniques & Modalities | 0.018433 | 0.470046 | 0.511521 |
| Interaction Beyond the Individual | 0.059603 | 0.417219 | 0.523179 |
| Learning, Education and Families A, Learning joint | 0.063158 | 0.463158 | 0.463158 |
| Learning, Education and Families B, Learning joint | 0.032609 | 0.543478 | 0.423913 |
| Privacy & Security | 0.068182 | 0.409091 | 0.522727 |
| Specific Application Areas | 0.046358 | 0.496689 | 0.456954 |
| Understanding People: Mixed and Alternative Methods | 0.113924 | 0.481013 | 0.405063 |
| Understanding People: Qualitative Methods | 0.078947 | 0.381579 | 0.539474 |
| Understanding People: Quantitative Methods | 0.074324 | 0.459459 | 0.466216 |
| User Experience and Usability A, User Experience and Usability joint | 0.081967 | 0.557377 | 0.360656 |
| User Experience and Usability B, User Experience and Usability joint | 0.049180 | 0.508197 | 0.442623 |
| Visualization | 0.046358 | 0.377483 | 0.576159 |
Student Volunteer
Become a Student Volunteer
The student volunteer organization is what keeps CHI running smoothly throughout the conference. You must have had student status for at least one semester during the academic year before CHI. We are more than happy to accept undergrad, graduate, and PhD students. We need friendly enthusiastic volunteers to help us out.
The SV lottery will be open on Monday, October 12, 2022, at new.chisv.org and will be closed on Monday, January 16, 2023. Approximately 180 students will be chosen as SVs for this year’s conference. All other students who registered will be assigned a position on the waitlist. To learn how the SV lottery works, please check the Student Volunteers page for more details. To sign up for the lottery, please visit new.chisv.org, select the appropriate conference, and follow the steps to enroll.
We will mainly be accepting IN-PERSON SVs for this year’s conference, however, we may end up needing some limited SVs to complete remote only tasks. SVs can state their preference during enrollment and the registration form can be updated at any time before the lottery is run. We encourage all applicants to update the form once your participation mode is clearer later in the year.
The lottery result will be announced on Monday, January 23, 2023. Once you have a confirmed spot and registration is open you will be required to register, usually in two weeks. You will receive instructions on how to do this with a special code that will waive your registration fee for the conference. You will still be responsible for course/workshop fees.
Important Dates
All times are in Anywhere on Earth (AoE) time zone. When the deadline is day D, the last time to submit is when D ends AoE. Check your local time in AoE.
- SV lottery registration open: Wednesday, Oct 12, 2022
- Close lottery: Monday, January 16, 2023
- Announce results: Monday, January 23, 2023
What Will I Do When I Volunteer?
For CHI2023 SVs, you will agree to a volunteer contract, in which you agree to:
- In-person SVs: Work at least 20 hours
- Show up on time to tasks
- Attend an orientation session
- Arrive at the conference by Sunday morning at the latest (in person SVs only)
In return we commit to:
- Waive your registration fee
- Provide 2 meals a day on site (breakfast and lunch)
- Free SV t-shirt to be collected on site
- Our fabulous SV thank-you party on Friday night (April 28, 2023). When you are planning for your travel we highly recommend that you remember to leave on Saturday or Sunday so you can attend the party. There is always food, drinks, dancing, and fun!
- More SV benefits TBA…
If you need to reach us, please always use the svchair@chi2023.acm.org address so that the three of us receive it. Reply-to-all on our correspondence so we all stay in the loop and can better help you.
A CHI 2023 note: With the rapid changing situations and CHI 2023 staying hybrid, there may be changes to the way the SV program will operate this year. We, the SV chairs, are monitoring the situation and will keep the community up to date on any changes to the SV program. If you have any comments or concerns, please feel free to email us at svchair@chi2023.acm.org.
Frequently Asked Questions
We get a lot of emails with the same kinds of questions, this is not a made up FAQ.
Q: I know the deadline for the lottery is passed, but I really, really want to be a student volunteer. Can you get me in?
A: You may go to new.chisv.org at any time after the lottery is opened or even after it is run to put your name in the running. If the lottery has already been run your name will simply be added to the end of the waiting list. If you will be attending CHI anyway there is always a chance you may be able to be added to the last minute, you never know.
Q: I want to skip orientation, or work way less than 20 hours, or arrive on Monday, can I still be an SV?
A: No, sorry these are minimum expectations we expect from everyone.
If after you commit extenuating circumstances appear (like volcanos erupting and other strange things) please communicate with us (to svchair@chi2023.acm.org). All we ask is for you to communicate what your circumstances are as early as you realize a situation has come up.
Q: I didn’t get your emails and/or forgot to register by the deadlines you guys sent us and I lost my spot as an SV, can I get it back?
A: If this is due to you just not reading your emails, not taking care of your responsibilities, not keeping your email up to date in our system, forgetting or similar things then the answer is NO, no you may not. If there are extenuating circumstances, please communicate with us (to svchair@chi2023.acm.org). All we ask is for you to communicate what your circumstances are as early as you realize a situation has come up. (Yes, we’ll repeat this often).
Q: I was nominated for an SV spot by someone and got in, will I have to do the same kind of work as other SVs?
A: Yes, the obligations are the same.
We are looking forward to meeting all of you!
Ciabhan Connelly, Georgia Institute of Technology, Atlanta, U.S.
Julia Dunbar, University of Washington, Seattle, Washington, U.S.
Maximiliane Windl, LMU Munich, Munich, Germany
Email: svchair@chi2023.acm.org
Understanding CHI Reviews: Analysis of CHI2022 Revise and Resubmit
Julie R. Williamson (Papers Co-Chair 2022 and 2023)
Tldr;
- Categorical recommendations are a better representation of reviewers’ views and a better indicator of paper outcomes.
- Ordinal recommendations are a poor indicator of paper outcomes, and lean towards a negative view of papers even when reviewers recommend acceptance.
- Rigour is the most important criteria in paper success, followed by significance, followed by originality.
Reflecting on CHI2022
The only things that are certain are death, taxes, and optimistic volunteers trying to improve the CHI reviewing process. In 2022, we introduced a revise and resubmit process that allowed for major revisions. This came with a lot of uncertainty, but was driven by a conviction that this would lead to a “better” review process, published papers, and author experience.
I’m writing this post in my capacity as Papers Co-Chair for CHI 2022 and 2023. I’m a faculty member at the University of Glasgow in immersive technologies, but I have extensive experience volunteering for SIGCHI and ACM in publications roles. The goal of this post is to review the data from CHI 2022 and help make the CHI 2023 process more transparent and consistent. This summary should help reviewers and authors with information that didn’t exist when we started the revise and resubmit process in 2022. Once the CHI 2023 reviews are released, we’ll write a follow-up post with an updated analysis.
A significant change that came with revise and resubmit was the removal of the ordinal “scores” in favour of a categorical “recommendation.” I was keen to move away from decision making on the flawed premise of averaged ordinal data. We removed the asymmetric nine point scale (from 1 – I would argue for rejecting this paper to 5 – I would argue strongly for accepting this paper) and replaced it with a categorical recommendation.
Reviewers could indicate one of five options; Accept (A), Accept or Revise/Resubmit (A/RR), Revise/Resubmit (RR), Revise/Resubmit or Reject (RR/X), Reject (X). This isn’t a perfect solution, but I argue it is substantially better than what we had before. There are limitations: variation between reviewers as to what could realistically be achieved in a revise/resubmit cycle, and confusion with other review processes using different terms or the same terms differently. Although we removed the primary ordinal score, we did not remove all ordinal data. Inspired by ACM’s Guidelines for Pre-Publication Review, we included four-point ordinal scales for Originality, Significance, and Rigour (Low, Medium, High, Very High, another asymmetric scale).
Ironically, in this analysis, I have averaged ordinal data, expressed categories as ordinal scales, and normalised ordinal scales, along with other tricks commonly used. I’ll point out anytime I’ve done this, and in some cases it will highlight how flawed these common practices are. In other cases, I’ll just recommend accepting the limitations of this kind of analysis, which is an acceptable uncertainty for reflection, but not deciding the fate of papers!
Recommendation or Rating?
This post aims to answer a key question from 2022: did changing from a score to a recommendation improve the process for paper decisions? I believe the data says yes.
Figure 1 (left) shows a histogram of the 2022 ordinal responses (originality, significance, rigour) for each paper (averaged across reviewers), split it into accepted and rejected papers, and rescaled to a five point scale for comparison. These averaged ordinal scores data show bell curves with a relatively large overlap between accepted and rejected papers. Figure 1 (right) shows a histogram of the categorical recommendations (represented as ordinal values and averaged) for accepted and rejected papers. The categorical data results in two clearly separated distributions, with rejected papers in a steep distribution centred on 1, and accepted papers in a relatively flat distribution spreading from 2 to 5.

That “noisy middle” is where we hope to see the most important discussions during the review process, but I argue that the overlap shown in these figures represents two semantically different discussions. On the left, the overlap represents differences in opinion on how a paper scores on a subjective scale, that is “I think that this paper is only ‘high’ on a four point scale,” On the right, the overlap represents differences in opinion on the preferred outcome of the paper, that is “I think this paper should be accepted.” I would argue that the overlap created by ordinal data is more representation of noise than overlap created by categorical data. This is important, as we’ll see in the next section!
Another issue highlighted by these visualisations is that the CHI community has a problem with negativity: on ordinal scales we don’t rate highly the papers we like and we don’t crush the papers we dislike. I couldn’t say whether this is simple bias towards the centre, or more complex social desirability bias, but the distributions above show that the ordinal data is a poor representation of what a reviewer means by their scores. Let’s unpack that further.
What do Reviewers Mean?
A commonly understood issue with ordinal scales is that the numbers on the scales mean different things to different people. In survey research, that measurement error is solved by carrying the difference over a large N. For any given paper we don’t have a large N. Within the CHI community, a common anecdotal argument for not implementing a fully anonymous review process is how “valuable” it is for the committee to see the reviewer names, for example “I know Julie always gives too high of a score so we should really be looking at this like it’s not that positive of a review.” This is the stuff of nightmares when we want a consistent and transparent review process.

The data confirms that reviewer recommendations vary widely when compared to the ordinal scores they give papers. There is a trend towards a lower score as reviewer recommendation is more negative, but the spread within a recommendation is substantial. Some reviewers gave ordinal scores as low as 2.1 when recommending accept, while others gave scores as high as 4.2 while recommending reject, and everything in-between.
This data confirms the semantic difference between the overlap in Figure 1 left and Figure 1 right. I would argue that the ordinal scores are only useful and reflective of reality when set alongside the categorical recommendation, and decisions should be made based on the categorical recommendation as the primary criteria. For 2023, we’ve improved how the categories will be viewable in aggregate in PCS, allowing subcommittees to sort more easily by category during the PC meeting.
What are the Most Important Criteria?
Moving away from a single ordinal scale toward multiple scales based on different criteria also gives us some insights into which criteria most impact the success of a paper. Some common questions the CHI community has grappled with: Is CHI too fixated on originality? Will a paper with low rigiour but a cool idea still be accepted? Do we not care enough about rigour?
To address this question, we performed a Bayesian logistic regression to estimate the strength of the (unnormalised) ordinal scores in predicting the ultimate accept/reject outcome. This model had the form:
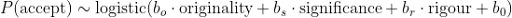
where the coefficient bo, bs, br and b0 were estimated. Using very weakly informative priors on the coefficients, we fitted the model with pymc3. A forest plot of the estimates is shown in Figure 3. All of the ordinal scores have some predictive power, but rigour has a substantially larger effect than significance or originality on the probability of a paper being accepted.

Many thanks to John Williamson who completed the logistic regression analysis for the criteria scales.
A successful paper will generally score well across all criteria, but the strongest predictor of success is rigour, followed by significance, followed by originality. This opens up some interesting questions, as the values associated with these criteria will vary broadly across different subcommittees and communities of practice. For 2023, we’ll continue using these criteria on the review form with some minor changes to standardise these scales to symmetric 5 point scales.
Categorical Decisions and Paper Outcomes
The proportion of reviewers who are positive about a paper in terms of categorical recommendation is the best indicator of paper outcomes. Figure 4 shows the number of papers that were Accepted or Rejected based on the proportion of reviewers who recommended revise and resubmit or better in 2022. About half of the submissions in 2022 had no reviewer recommending revise and resubmit or better. Not a single paper in this category was ultimately accepted in 2022.

Based on this data, we set the threshold for revise and resubmit in 2023: at least one reviewer or 1AC must recommend revise and resubmit or better for authors to have the opportunity to revise and resubmit. This means any single reviewer or AC can “save” a paper even if all others recommend reject. But it’s clear that a greater proportion of positive reviewers leads to a higher chance of success in the revise and resubmit cycle. In 2022, if only one reviewer was positive, it’s very likely your paper was ultimately rejected. If most reviewers were positive, it’s very likely your paper was accepted. When authors receive their reviews in November 2023, if they meet the threshold for revise and resubmit they must also consider how positive their reviews are when determining if they want to go through the revision cycle.
Open Questions
To conclude, I’ll leave some open questions that I think this data exposes and that will be interesting to reflect on as we enter the CHI 2023 review process.
Does a categorical recommendation instead of an ordinal score lead to a better decision process? I believe the data says yes. The recommendation is a better indicator of reviewers’ views when compared with the ordinal scales, and both authors and programme committees can have more consistent expectations going into the PC meeting using categorical recommendations for decisions. There is still an open concern that before reviews are released, it can be hard to predict which papers will be successful. Changing the review form won’t fix this, but I hope the reducing noise in the decision process is a step in the right direction.
What makes a rigorous paper? The strongest predictor of paper success was rigour, but it is clear that what rigour means and how it is assessed will vary widely across the subcommittees and different communities of practice. Beyond the ordinal scales, we don’t have review process data or programme metadata that would give us further insights on rigour. One approach I would like to see is incorporating artefact metadata into conference proceedings, and as a community exploring the wide range of artefacts that underpin our work.
Does Revise and Resubmit lead to better papers? In this analysis, I didn’t look at how papers changed after revise and resubmit, or any broader metrics of “quality” with respect to the final programme. This is a more complex issue than analysing ordinal data can achieve, but it’s something we should be reflecting on in the revise and resubmit process.
Notes
The data is by definition incomplete because submissions conflicted with me are not included. Totals will not add up to some published numbers for this reason. Thanks to my co-chairs in 2022, 2023, and the volunteers who provided feedback on this work.
Stefanie Mueller, Julie R. Williamson, Max Wilson
CHI 2023 Papers Chairs
Steven Drucker, Julie R. Williamson, Koji Yatani
CHI 2022 Papers Chairs
Scales
CHI 2021 “Score” Scale
Strong Accept: I would argue strongly for accepting this paper; 5.0
. . . Between possibly accept and strong accept; 4.5
Possibly Accept: I would argue for accepting this paper; 4.0
. . . Between neutral and possibly accept; 3.5
Neutral: I am unable to argue for accepting or rejecting this paper; 3.0
. . . Between possibly reject and neutral; 2.5
Possibly Reject: The submission is weak and probably shouldn’t be accepted, but there is some chance it should get in; 2.0
. . . Between reject and possibly reject; 1.5
Reject: I would argue for rejecting this paper; 1.0
CHI 2022 Ordinal Scales (Originality, Significance, Rigour)
Very High
High
Medium
Low
Data Tables
These tables provide a numerical representation for Figures in this post.
Figure 1 Left (Ordinal Scores)
Figure Description: Histogram of paper scores averaged from the ordinal scales and normalised onto 5 point scale. Separated by accepted and rejected papers, resulting bell curves overlap between 2.5 and 3.5. See data table:
| Bin Right Edge (Accepted Papers) |
Count (Accepted Paper) |
Bin Right Edge (Rejected Papers) |
Count (Rejected Papers) |
|---|---|---|---|
| 2.45 | 14 | 1.51 | 24 |
| 2.71 | 26 | 1.77 | 63 |
| 2.97 | 59 | 2.03 | 224 |
| 3.23 | 72 | 2.29 | 284 |
| 3.49 | 68 | 2.55 | 500 |
| 3.75 | 104 | 2.81 | 299 |
| 4.01 | 54 | 3.07 | 269 |
| 4.27 | 56 | 3.33 | 63 |
| 4.53 | 66 | 3.59 | 25 |
| 4.79 | 93 | 3.85 | 2 |
Figure 1 Right (Categorical Recommendation)
Figure Description: Histogram of paper scores from recommendation category represented as a 5 point scale. Separated by accepted and rejected papers, rejected papers have a steep falloff from 1 to 3.5, accepted papers have a relatively flat distribution from 2 to 5. See data table:
| Bin Right Edge (Accepted Papers) |
Count (Accepted Paper) |
Bin Right Edge (Rejected Papers) |
Count (Rejected Papers) |
|---|---|---|---|
| 2.3 | 14 | 1.25 | 392 |
| 2.6 | 26 | 1.5 | 397 |
| 2.9 | 59 | 1.75 | 349 |
| 3.2 | 72 | 2.0 | 276 |
| 3.5 | 68 | 2.25 | 148 |
| 3.8 | 104 | 2.5 | 100 |
| 4.1 | 54 | 2.75 | 44 |
| 4.4 | 56 | 3.0 | 38 |
| 4.7 | 66 | 3.25 | 10 |
| 5 | 93 | 3.5 | 8 |
Figure 2 (Boxplot)
Figure description: Boxplot of reviewer ordinal responses grouped by categorical recommendation. Plot shows significant overlap between all categories, with a downward trend in median from accept to reject. See data table:
| Accept | Accept or RR | RR | RR or Reject | Reject | |
|---|---|---|---|---|---|
| Max | 5.0 | 5.0 | 5.0 | 5.0 | 4.1 |
| Upper Quartile | 4.2 | 3.8 | 3.3 | 2.9 | 2.5 |
| Median | 3.8 | 3.3 | 2.9 | 2.5 | 2.1 |
| Lower Quartile | 3.3 | 2.9 | 2.5 | 2.5 | 1.7 |
| Min | 2.1 | 2.1 | 1.25 | 1.25 | 1.25 |
Figure 3 (Forest Plot)
Figure Description: Forest plot shows relative predictive power of ordinal scales for paper success. Rigour has the strongest predictive power, following by significance, following by originality. See data table:
| Median | HDI 3% | HDI 97% | |
|---|---|---|---|
| Originality | 1.305 | 0.972 | 1.650 |
| Significance | 2.163 | 1.797 | 2.524 |
| Rigour | 2.690 | 2.364 | 3.016 |
Figure 4 (Bar Chart)
Figure Description: Bar chart showing proportion of reviewer with favourable recommendation grouped by paper outcome as Accept or Reject. The greater proportion of favourable reviews, to greater likelihood of eventual acceptance. See data table:
| Accept | Reject | |
|---|---|---|
| 0% | 0 | 1151 |
| 25% | 9 | 449 |
| 50% | 52 | 137 |
| 75% | 175 | 21 |
| 100% | 379 | 5 |
Welcome to CHI 2023!
On behalf of our organizing committee, we’d like to welcome you to CHI2023! CHI2023 will be held in Hamburg, Germany – we are truly excited about the city and the venue. We will be having a hybrid conference – stay tuned for the details as we move forward with planning the details.
The theme of CHI 2023 is “reCHInnecting”. By this we refer to re-establishing contacts in the post-pandemic world with the colleagues in our global community, both online and physically present. We also want to strengthen the connections between academia and industry, and hence CHI2023 will put special effort in fostering practically relevant content, besides scientific excellence.
CHI’23 AC Volunteering
In a few weeks, the CHI’23 paper chairs and SCs will start recruiting ACs for CHI’23. If you like to be considered, please go to https://new.precisionconference.com/ and on the submissions page select ‘SIGCHI’ -> ‘CHI 2023’ -> ‘CHI 2023 AC Volunteering’ from the dropdown menu, then fill out the volunteer form. The form has been streamlined this year to make volunteering easier, the simplified form should only take a few minutes to fill out. The volunteer form will close April 25 end of day anywhere on earth.
(more…)
CHI 2023 Sponsors
Hero


Champion

Contributing


